
Statistical Machine Learning - Who Tweeted That?
The goal of this project is to predict the authors of test tweets based on the analysis of the 328195 unstructured training tweets from 9293 users.
Feature Engineering
The classification problem requires us to go through tweets from large number of authors. The number of tweets for an individual varied from a single tweet to well over 200 tweets. Training models using the whole corpus was very expensive. To overcome this problem, we applied different feature engineering techniques:
- Preprocessing: Tweets are unstructured, and it is challenging to perform semantic analysis on them. Hence we performed preprocessing such as converting the words to lower case, removing special characters, removing hyperlinks, removing stopwords from tweets and using stemming and lemma to reduce the number of unique words thereby reducing the features.

- Feature creation: We began by creating some of our own features based for the preliminary analysis. We generated features based on some of the common properties such as retweets used, foreign language detected, number of capital letters proportion, number of unrecognised words, number of tags, number of hashtags and usage of URL in text. We were not able to get good classification training accuracy using this approach.
- Vectorization: We realised that textual content is important for acquiring better accuracy. Hence we tried vectorising preprocessed tweets. In order to vectorise the tweets to features, we have used different libraries. Using CountVectorizer, we converted the words of cleaned tweets to a matrix based on the token count. We restricted the number of features and tuned the document frequency. As there was not much improvement in the accuracy, we explored TfidfVectorizer. We used training data to create a corpus. Tf-idf assigns a numerical value based on statistics that reflects the importance of words. We also investigated implementing the HashingVectorizer. It uses one-way hashing to convert string to features by applying the hashing function. Lastly, we tried Word2Vec for performing vectorisation of the tweets based on some textual semantics. Turns out, TfidfVectorizer provided the most optimal classification accuracy out of all other vectorizers. We have also applied feature selection and elimination technique to identify the most relevant features using a variance threshold as a part of the pipeline.

- Language Modelling: In order to improve accuracy and performance, we also explored Embedding layer of Keras sequential neural network design. Using this layer, we were able to map tweet texts into tensors with input and output dimension, which can be feed into a neural network for understanding patterns and semantics. Finally, we moved to pre-trained language model learner approach used in transfer learning. In order to implement this, we used pre-trained Wikipedia’s model provided by fast.ai library and fine-tuned it with raw twitter data without any preprocessing. Using this language modelling approach, we were able to get the best accuracy on the test data.
Learners
Our requirement was to tackle a multi-class text classification problem. In order to solve this problem with the most appropriate learner, we explored several categories of the models:
- Multiclass as One-Vs-All models: The first model we executed was a Linear Support-Vector machine. A support-vector machine’s ability to construct hyperplane or set of hyperplanes in a high or infinite-dimensional space, allowed us to form a suitable classifier to classify tweets. SVMs’ ability to not overfit the problem was ideal given we were testing on 30% data on Kaggle. We then experimented with Stochastic Gradient Classifier on top of SVM. The SGD classifier’s use of SVM in combination with gradient descent optimiser to randomly select (or shuffled) samples allows calculating gradients efficiently. However, the results did not greatly alter from the one-vs-rest SVM model developed previously.
- Inherently multiclass Models: We then implemented Random forest classifier. The model’s ability to use a multitude of decision trees(15 in our model) and choosing the best possible class allowed us to classify a tweet to a specific author. Next we implemented a Naive Bayes Classifier. Naive Bayes classifiers are a family of simple “probabilistic classifier” based on Bayes’ theorem with strong (naive) independence assumptions between the features. We have trained the classifier for each author based on a set of keywords that the author has previously used. While predicting a new tweet, we evaluate certain keywords in it and use our classifier to predict the author. We also created a Multinominal Logistic Regression model as it allowed us to acquire probabilities that a tweet belonged to a certain author and predict an author with the highest probability.
- Keras sequential networks: The next set of models we implemented were the Recurrent Neural Networks(RNN). The RNN’s ability to understand the patterns, along with using keywords and vectorised features, allowed better classification. Also, its ability to have persistent information allows it to keep learning from its past iteration. Keras deep learning neural networks using Tf-Idf vectorizer uses this concept to classify tweets to authors. Even though RNNs allow us to persist information, it does not hold information for entirely like Long Short Term Memory Models(LSTMs). Hence, we used Keras with LSTMs along with embedding. The accuracy with the changes remained quite similar.
- Pretrained models: Our final model was based on pre-trained LSTM model called ULMFiT (Universal Language Model Fine-tuning for Text Classification) from fast.ai. The model is pre-trained on 103 million tokens extracted from Wikipedia. The pre-trained model is competent enough to understand the semantics of the text. Once, we form a final tuned model using the collection of tweets. We get a classifier that can use both semantic and syntactic patterns in the text to classify tweets. The architecture below depicts how the pre-trained model can be transformed to fit a specific application using fine-tuning.
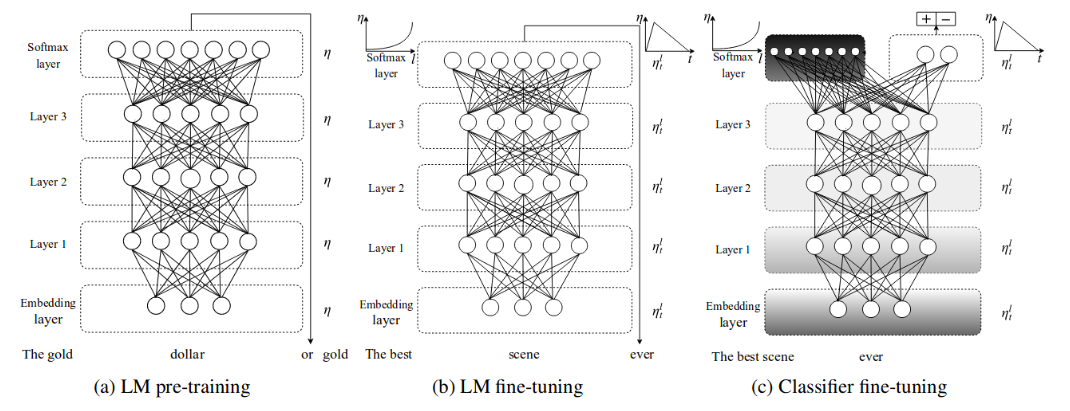
Model selection
We aimed to find a generalised model for this problem which can provide the most optimal training accuracy without overfitting. We explored multiple learners with different feature selection techniques, as explained in the previous section to get a model which can generate good predictions on the test data.
Our approach was to start with fewer classes which have a high frequency of tweets and test models with a combination of different learners and feature engineering techniques to get comparable classification training accuracy score. The results of different learners are compared with each other using categorisation accuracy of a different number of classes summarised in the table below. Using this comparison table, we can infer the following results for selecting the most appropriate model:
- Multiclass as One-vs-All models: Using feature selection on TF-IDF vectorizer in combination with multiclass as one-vs-all models, we were able to get decent results with 28 classes that have at least 200 tweets. LinearSVC with TF-IDF vectorizer performed 47% better than Word2Vec. In comparison, SGDClassifier gave almost the same performance with TF-IDF. As we increase classes that have at least 100 tweets, all the models from this category start taking a major hit in the accuracy where only the SGDClassifier trained on a large number of classes provided 8% accuracy. Consequently, we discarded this entire category for model selection and moved to other models.
- Inherently multiclass models: In these models, we tried to explore multiclass classification training techniques with different feature engineering approaches. Naive-Bayes with TF-IDF gave almost the same accuracy in comparison to Logistic Regression and RandomForest with 15 estimators. These models are not able to give better results than the previous category, and they were either extremely slow or memory-intensive when trained for a large number of classes.
- Keras sequential networks: Our basic multiclass models are either too slow to train or causing memory blowup for large number of classes which pushed us to explore options in neural networks. We tried implementing a Recurrent Neural Network using keras library with basic relu and softmax activation function which gave decent results for less classes but started getting extremely slow to train as we increase classes. We tried tweaking the sequential layers by adding embedding layer with LSTM to get better results. It turns out the model is now more slower to train, though it was able to maintain accuracy.
- Pretrained models: Using Keras library to build RNNs, we realised that we could go around the memory overflow issue if we train our model in batches which is how neural network works. In order to solve the slow training problem, we started exploring the pre-trained models, which helped us to implement transfer learning. ULMFiT implementation using fast.ai library provided us with the tools to train our custom twitter text based language model, using pre-trained knowledge of Wikipedia’s content. Using this type of learning, we were able to get excellent results for fewer classes (63%). We were also able to train the model for a large number of classes in a decent amount of training time and without any exponential memory blowup with better results (26%). Also, this model shows no sign of overfitting and provides consistent testing accuracy when compared with training for 8973 classes (atleast 10 tweets per class), as shown in Figure 2. Hence, we selected this as our final model for this problem.
| Learners | Classes | |||
|---|---|---|---|---|
| 28 | 381 | 5592 | 8973 | |
| LinearSVC (Word2Vec) | 0.1780 | 0.1123 | % | % |
| LinearSVC (Tf-Idf) | 0.5015 | 0.3868 | x | % |
| SGDClassifier (Tf-Idf) | 0.4907 | 0.3801 | 0.1545 | 0.081 |
| RandomForest (Tf-Idf) | 0.4612 | 0.3499 | x | % |
| Logistic Regression (Tf-Idf) | 0.4829 | 0.3348 | x | % |
| Naive-Bayes (Tf-Idf) | 0.4622 | 0.2806 | x | % |
| Keras (Tf-Idf) | 0.4667 | 0.3112 | % | % |
| Keras LSTM (Embedding) | 0.4579 | 0.3123 | % | % |
| ULMFiT (Modelling) | 0.6390 | 0.5531 | 0.3051 | 0.260 |
Comparison of training accuracy (x - memory overflow, % - extremely slow)
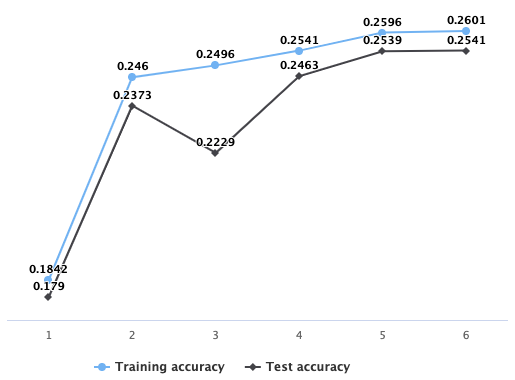
ULMFiT performance on Kaggle
Critical analysis
We implemented a range of feature extraction techniques. Tf-Idf’s procedure of giving weights to words by combining the frequency of a word in a tweet along with the uniqueness of the word in the corpus gave useful features. However, training a model using all the features extracted from Tf-Idf became computation and memory-wise expensive. On the other hand, Count Vectorizer and Hashing functions do not look into the entire dataset for feature engineering. Word2Vec is based on extracting features from the semantic structure of the text, and due to tweets being unstructured, it did not perform well. Feature extraction using Word Embeddings gave similar results as Tf-Idf, as embedding tries to find connections between words in an unstructured tweet. We were able to extract the best features for classification using a pretrained language model based on Wikipedia text. The model’s prior features allowed us to understand the syntactic and semantic aspects of tweets in a much better way.
Transfer learning implemented using pre-trained text model provided the most optimal results for this problem. This approach performed better than any other learners due to its underlying ability to learn semantics from the twitter text based on already learned text data. Multiclass models failed as they were relying heavily on the vectorised information provided using TF-IDF which is not able to retain semantic relationships even after using 2-3 ngrams. Moreover, One-vs-All models try to place one classifier for every class to solve the multiclass classification problem which becomes too memory-intensive for a large number of classes. Similarly, Inherently multiclass models suffers from the same drawback of memory blowup and slow training due to their need for extreme data-intensive operations for learning this kind of problem and generate predictions.
On the other hand, Keras sequential networks solve memory issues due to their training algorithm’s ability to learn in batches but they are not able to provide decent performance gain even after using LSTM and embedding layers. One of the reasons for this failure is the inability of the embedding layer to extract essential and crucial tokens for the learning. The pre-trained language models of ULMFiT handle this drawback. It tries to place appropriate flags around tokens in order to understand patterns and relationships among the text. Due to this extremely productive modelling, we were able to create a classification model with 26.01% training accuracy, which is not attained by any other mentioned learner.
Cheers!



Leave a comment