
Cluster & Cloud Computing - Twitter Data Processing (Spartan HPC)
This project aims at delivering a simple, parallelised application that leverages the power of the University of Melbourne High-Performance Computing(HPC) facility named SPARTAN. Using TwitterGeoProcessor package, a large dataset of geocoded twitter file can be explored and analysed for extracting relevant information such as the number of posts in individual regions and trending hashtags in each one those regions. The package has been implemented on python and designed with the concepts of MPI (Message-Passing Interface) for effectively improving the performance of processing on the HPC environment.
Complete project source: https://github.com/abhinavcreed13/ProjectTGProcessing
Task Description
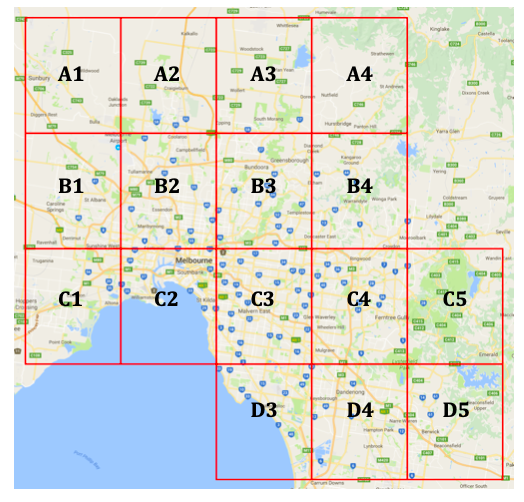
This application is required to search a large geocoded Twitter dataset to identify tweet hotspots around Melbourne.
Specifically, the application should:
- Order(rank) the Grid boxes(regions) based on the total number of tweets made in each box and return the total count of tweets in each box, e.g.
- C3: 23,456 posts,
- B2: 22,345 posts,
- D1: 21,234 posts,
- …
- Down to the square with the least number of posts;
- Order(rank) the top 5 hashtags in each Grid boxes(regions) based on the number of occurrences of those hashtags in each box.
- C3: ((#maccas, 123),(#qanda, 121),(#trump,100),(#unimelb,66),(#dominos,41))
- B2: ((#maccas, 82),(#vicroads,81), etc etc….)
- …
- Down to the top 5 hashtags in the grid cell with the least number of posts;
Implementation Approach
After implementing various possible solutions, we are able to get the best performance using line-by-line processing of data. We have used the mpi4py python package for leveraging the power of MPI in python. In this approach, we process one object at a time for extracting region and hashtags and this can be done parallelly depending upon the number of processors provided. After the required data is extracted, it is then merged and reduced to produce the desired output.
This approach can be stated as the following steps:
- Initiate Master-child processor: As the application starts, we initiate processor functions for master-node and child-nodes, if the request is to run on multiple cores and data from melbGrid.json is extracted into parsed JSON object which is then passed to the running nodes.
- Read large data file iteratively: Both master and child node threads create independent handles of the file and read the data line-by-line. We have avoided the loading of entire JSON data in the memory since it can raise memory overflow exceptions for large datasets.
- Distributing data as per line index: Each thread processes different line number, using the logic of mod function applied to the total number of parallel nodes and the rank of an individual process. Every node including the master nodes processes the data in parallel.
if <node_rank> equals <line_number> mod <total_number_of_node>
then { process the line }
else { ignore the line, move to next one }
- Preprocessing of data : Program preprocesses the fetched data to check if it can be parsed into a valid JSON object, avoiding unknown JSON parsing exceptions.
- Extracting required data: From the parsed valid JSON object, relevant information such as id, text, coordinates and hashtags are extracted using basic selection and regular expression.
- Extract region: The region of the object can be attained using grid JSON object provided from the master node.
- Extract hashtags: Extract the hashtags from the tweet and add them against region key. Keep the count of hashtags by incrementing already existing entries.
- Collecting distributed data & reducing to desired output: Steps 4 to 7 are processed iteratively until all the lines exhausted. Next, the master node collects the final data from child nodes. This collected data is merged and reduced using the custom algorithm of O(n) complexity to get desired output most efficiently.
Package Structure
TwitterGeoProcessor
|──── TwitterGeoProcessor # Main Python Package
|────── lib
|──────── mpi_geo_manager.py # MpiGeoManager class for MPI-driven processing
|──────── utilities.py # Utilities class for common functions
|────── twittergeoprocessor.py # TwitterGeoProcessor class for processing & analysing results
|──── out-files
|────── slurm-7951179.out # 1-node-8-cores output file
|────── slurm-7951199.out # 2-nodes-8-cores output file
|────── slurm-7951206.out # 1-node-1-core output file
|──── slurm-job
|────── one_node_eight_cores_big.slurm
|────── one_node_one_core_big.slurm
|────── two_nodes_eight_cores_big.slurm
|──── tweet_crawler.py # Script file to use TwitterGeoProcessor package
Invocation
The execution of this application starts from tweet_crawler.pyscript file. This execution is triggered by submitting slurm job on SPARTAN server as per the configuration provided. We have created 3 slurm files for different configurations: 1-node-1-core, 1-node-8-cores and 2-node-8-cores (4-core/node).
Commands of invocation for 1-node-8-cores slurm file can be explained as:
#!/bin/bash
#SBATCH --nodes=1
This command defines the number of nodes for process execution
#SBATCH --ntasks=8
This command defines the number of cores for process execution
#SBATCH --time=0-00:02:00
This command defines the wall-time for process
#SBATCH --partition=cloud
This command defines a partition on which process will run
module load Python/3.5.2-goolf-2015a
This command will load the required module for running the script
echo "---- 1-node-8-cores/big ------"
time mpirun -n 8 python3 tweet_crawler.py -d bigTwitter.json
This command will start the script by taking a parameter which specifies which file to process and produce results.
Challenges Faced
Some of the challenges we faced while creating the most efficient application:
- Avoiding memory-overflow: It was challenging to load large twitter dataset file using normal JSON loading methods since it can cause memory overflow issue due to its large size of the dataset.
- Choosing the most efficient data structure: One of the most crucial steps was to decide the most effective data structure which can save processing time. We used hashmaps which reduced the complexity from \(O(n^3)\) to \(O(n)\).
- Exploring parallelizable code sections/logic: Writing the code from parallelism perspective, in order to reduce the serial code to optimize the usage of multiple cores.
Results and Analysis
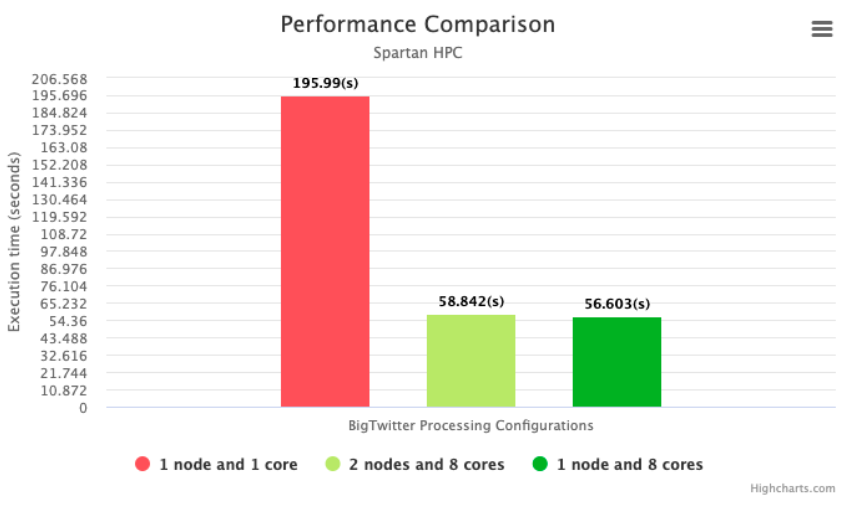
Using MPI framework for the multithreaded application we were able to achieve the output in less time. We have used the comparison parameter to be the number of seconds it took for a test case to run in different scenarios.
We ran three test case, as mentioned below.
- One node one core: In this scenario, the application ran serially since we did not have multiple cores to run the program in parallel. We were able to extract the required output in 195.99 seconds.
- One node eight core: In this scenario, we ran part of our application in parallel using the eight core. Parallel processing helped us in reducing the time spent by almost four times. We were able to extract the required output in 56.603 seconds.
- Two nodes eight core: In this scenario, we ran part of our application in parallel using the eight-core distributed across two nodes(4 cores each). Parallel processing helped us in reducing the time spent by almost four times. We were able to extract the required output in 58.842 seconds.
We observed that the application was able to improve the efficiency by 4 when we ran it on multiple cores.
Our observation is in alignment with the Amdahl's law which states that the increase in the efficiency is proportional to the parallelizable part of the application. Hence we could not achieve efficiency by a factor of 8 even with multiple cores runnings in parallel.
Also, we noted that there was no significant difference in runtime for the case with eight cores on one node and four cores on two nodes each.
Cheers!



Leave a comment