
Artificial Intelligence - Reinforcement Learning
This project will implement value iteration and Q-learning. It will first test agents on Gridworld (from class), then apply them to a simulated robot controller (Crawler) and Pacman.
Code base: UC Berkeley - Reinforcement learning project
Github Repo: https://github.com/abhinavcreed13/ai-reinforcement-learning
Task 1: Value Iteration
Recall the value iteration state update equation:
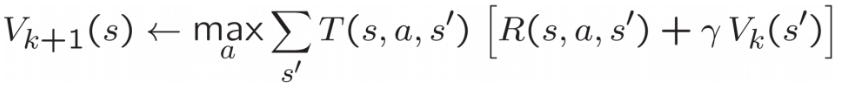
Write a value iteration agent in ValueIterationAgent, which has been partially specified for you in valueIterationAgents.py. Your value iteration agent is an offline planner, not a reinforcement learning agent, and so the relevant training option is the number of iterations of value iteration it should run (option -i) in its initial planning phase. ValueIterationAgent takes an MDP on construction and runs value iteration for the specified number of iterations before the constructor returns.
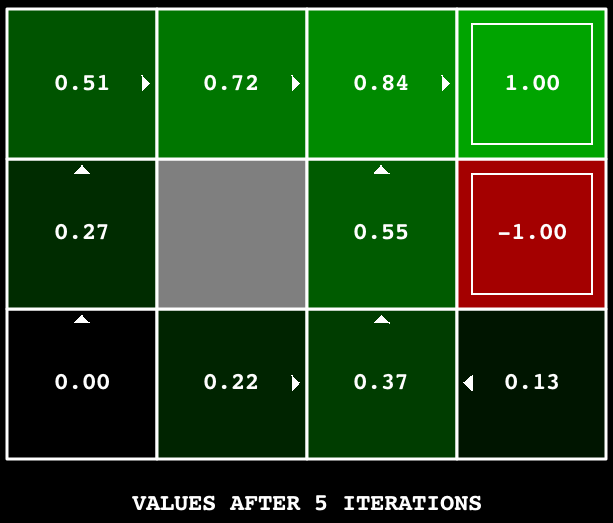
Hint: On the default BookGrid, running value iteration for 5 iterations should give you this output:
python gridworld.py -a value -i 5
Implementation:
https://github.com/abhinavcreed13/ai-reinforcement-learning/blob/main/valueIterationAgents.py#L34
Task 2: Bridge Crossing Analysis
BridgeGrid is a grid world map with the a low-reward terminal state and a high-reward terminal state separated by a narrow “bridge”, on either side of which is a chasm of high negative reward. The agent starts near the low-reward state. With the default discount of 0.9 and the default noise of 0.2, the optimal policy does not cross the bridge. The default corresponds to:
python gridworld.py -a value -i 100 -g BridgeGrid --discount 0.9 --noise 0.2

Implementation
https://github.com/abhinavcreed13/ai-reinforcement-learning/blob/main/analysis.py#L22
Task 3: Policies
Consider the DiscountGrid layout, shown below. This grid has two terminal states with positive payoff (in the middle row), a close exit with payoff +1 and a distant exit with payoff +10. The bottom row of the grid consists of terminal states with negative payoff (shown in red); each state in this “cliff” region has payoff -10. The starting state is the yellow square. We distinguish between two types of paths: (1) paths that “risk the cliff” and travel near the bottom row of the grid; these paths are shorter but risk earning a large negative payoff, and are represented by the red arrow in the figure below. (2) paths that “avoid the cliff” and travel along the top edge of the grid. These paths are longer but are less likely to incur huge negative payoffs. These paths are represented by the green arrow in the figure below.
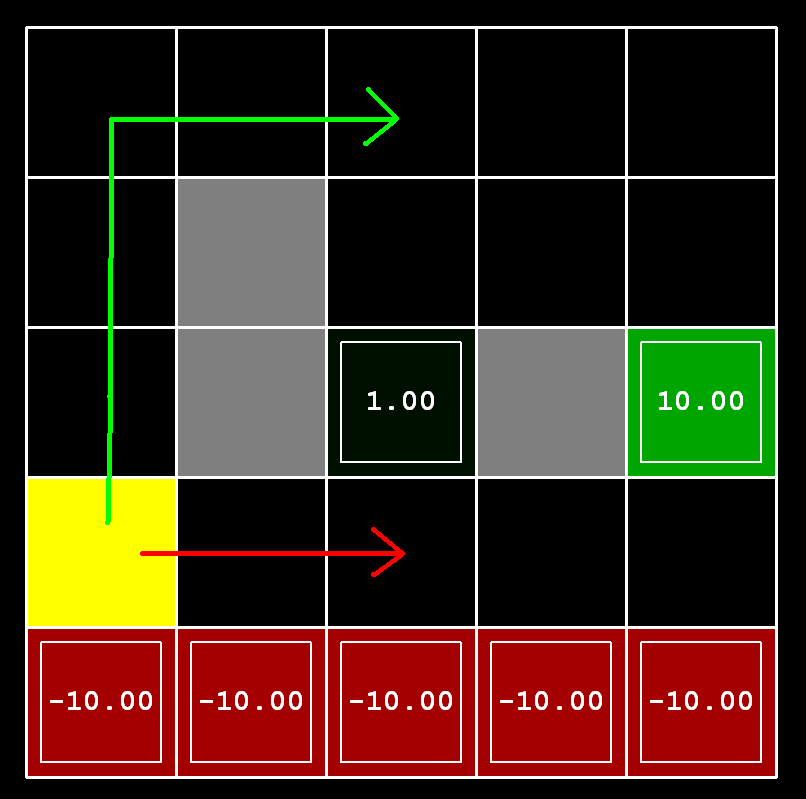
In this task, you will choose settings of the discount, noise, and living reward parameters for this MDP to produce optimal policies of several different types.
Here are the optimal policy types you should attempt to produce:
- Prefer the close exit (+1), risking the cliff (-10)
- Prefer the close exit (+1), but avoiding the cliff (-10)
- Prefer the distant exit (+10), risking the cliff (-10)
- Prefer the distant exit (+10), avoiding the cliff (-10)
- Avoid both exits and the cliff (so an episode should never terminate)
Implementation
https://github.com/abhinavcreed13/ai-reinforcement-learning/blob/main/analysis.py#L27
Task 4: Asynchronous Value Iteration
Write a value iteration agent in AsynchronousValueIterationAgent, which has been partially specified for you in valueIterationAgents.py. Your value iteration agent is an offline planner, not a reinforcement learning agent, and so the relevant training option is the number of iterations of value iteration it should run (option -i) in its initial planning phase. AsynchronousValueIterationAgent takes an MDP on construction and runs cyclic value iteration (described in the next paragraph) for the specified number of iterations before the constructor returns. Note that all this value iteration code should be placed inside the constructor (__init__ method).
Implementation:
https://github.com/abhinavcreed13/ai-reinforcement-learning/blob/main/valueIterationAgents.py#L126
Task 5: Prioritized Sweeping Value Iteration
You will now implement PrioritizedSweepingValueIterationAgent, which has been partially specified for you in valueIterationAgents.py. Note that this class derives from AsynchronousValueIterationAgent, so the only method that needs to change is runValueIteration, which actually runs the value iteration.
Implementation:
https://github.com/abhinavcreed13/ai-reinforcement-learning/blob/main/valueIterationAgents.py#L167
Task 6: Q-Learning
Note that your value iteration agent does not actually learn from experience. Rather, it ponders its MDP model to arrive at a complete policy before ever interacting with a real environment. When it does interact with the environment, it simply follows the precomputed policy (e.g. it becomes a reflex agent). This distinction may be subtle in a simulated environment like a Gridword, but it’s very important in the real world, where the real MDP is not available.
You will now write a Q-learning agent, which does very little on construction, but instead learns by trial and error from interactions with the environment through its update(state, action, nextState, reward) method. A stub of a Q-learner is specified in QLearningAgent in qlearningAgents.py, and you can select it with the option '-a q'. For this question, you must implement the update, computeValueFromQValues, getQValue, and computeActionFromQValues methods.
Implementation:
https://github.com/abhinavcreed13/ai-reinforcement-learning/blob/main/qlearningAgents.py#L21
Task 7: Epsilon Greedy
Complete your Q-learning agent by implementing epsilon-greedy action selection in getAction, meaning it chooses random actions an epsilon fraction of the time, and follows its current best Q-values otherwise. Note that choosing a random action may result in choosing the best action - that is, you should not choose a random sub-optimal action, but rather any random legal action.
You can choose an element from a list uniformly at random by calling the random.choice function. You can simulate a binary variable with probability p of success by using util.flipCoin(p), which returns True with probability p and False with probability 1-p.
Implementation:
https://github.com/abhinavcreed13/ai-reinforcement-learning/blob/main/qlearningAgents.py#L89
Task 8: Bridge Crossing Revisited
First, train a completely random Q-learner with the default learning rate on the noiseless BridgeGrid for 50 episodes and observe whether it finds the optimal policy.
python gridworld.py -a q -k 50 -n 0 -g BridgeGrid -e 1
Now try the same experiment with an epsilon of 0. Is there an epsilon and a learning rate for which it is highly likely (greater than 99%) that the optimal policy will be learned after 50 iterations?
Solution:
https://github.com/abhinavcreed13/ai-reinforcement-learning/blob/main/analysis.py#L62
Task 9: Q-Learning and Pacman
Time to play some Pacman! Pacman will play games in two phases. In the first phase, training, Pacman will begin to learn about the values of positions and actions. Because it takes a very long time to learn accurate Q-values even for tiny grids, Pacman’s training games run in quiet mode by default, with no GUI (or console) display. Once Pacman’s training is complete, he will enter testing mode. When testing, Pacman’s self.epsilon and self.alpha will be set to 0.0, effectively stopping Q-learning and disabling exploration, in order to allow Pacman to exploit his learned policy. Test games are shown in the GUI by default. Without any code changes you should be able to run Q-learning Pacman for very tiny grids as follows:
python pacman.py -p PacmanQAgent -x 2000 -n 2010 -l smallGrid
Implementation:
https://github.com/abhinavcreed13/ai-reinforcement-learning/blob/main/qlearningAgents.py#L135
Task 10: Approximate Q-Learning
Implement an approximate Q-learning agent that learns weights for features of states, where many states might share the same features. Write your implementation in ApproximateQAgent class in qlearningAgents.py, which is a subclass of PacmanQAgent.
Implementation:
https://github.com/abhinavcreed13/ai-reinforcement-learning/blob/main/qlearningAgents.py#L167
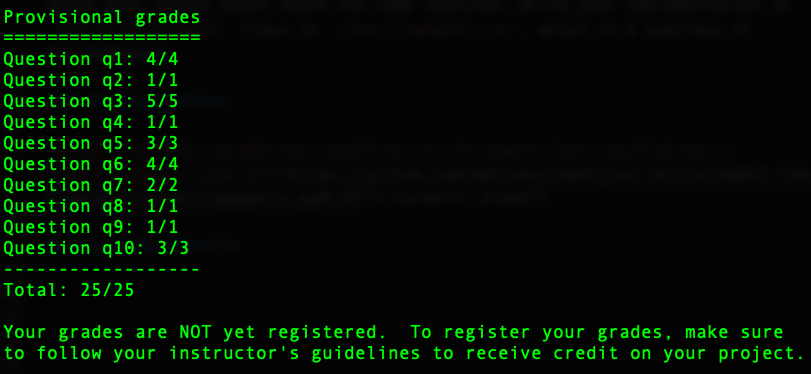
Autograder Results
Cheers!



Leave a comment