
Neural Probabilistic Language Model (NPLM) aims at creating a language model using functionalities and features of artificial neural network. In 2003, Bengio’s paper on NPLM proposes a simple language model architecture which aims at learning a distributed representation of the words in order to solve the curse of dimensionality.
In this post, we will be implementing the proposed NPLM using pytorch with GPU acceleration. The complete paper can be accessed using below url.
Bengio’s Paper: http://www.jmlr.org/papers/volume3/bengio03a/bengio03a.pdf
Objective
Our task is to create a trigram NPLM using the proposed architecture and then use it to calculate word similarities of certain words.
The primary objective of this post is to understand how language model can be easily implemented using pytorch.
For this, we will be using brown corpus provided by NLTK which will give us several paragraphs for training and tuning our model. After training, we will calculate word similarities of the following words:
computerandkeyboard(should be similar)dogandcat(should be similar)dogandcar(not similar)catandkeyboard(not similar)
Here, similarity means the chance of these words occurring in the same context or occurring nearby.
Load Brown Corpus
First, we need to load brown corpus. This can be easily done using NLTK interface as shown below.
import nltk
import csv
from nltk.corpus import brown
from nltk.corpus import wordnet
nltk.download("brown")
nltk.download("wordnet")
len(brown.paras())
## [nltk_data] Downloading package brown to /root/nltk_data...
## [nltk_data] Unzipping corpora/brown.zip.
## [nltk_data] Downloading package wordnet to /root/nltk_data...
## [nltk_data] Unzipping corpora/wordnet.zip.
## True
## 15667
We are having 15667 paragraphs in brown corpus.
Creating training and development set
As we’ll be building a trigram neural language model, the next step is to collect trigrams to construct our training data.
In a trigram neural language model, for example if we have the trigram cow eats grass, the input to the model is the first two terms of a trigram (cow and eats), and the language model’s aim is to predict the last term of the trigram (grass).
We will construct the training and development data for the language model where first 12K paragraphs will serve as our training data, and the remaining 3K+ will be for development. We will need to map words into IDs when constructing the training and development data. Any words that are not in vocab should be mapped to the special $<$UNK$>$ symbol.
As an example, given the sentence “a big fat hungry cow .”, we are trying to create the following training examples:
| input | target |
|---|---|
| a, big | fat |
| big, fat | hungry |
| fat, hungry | cow |
| hungry, cow | . |
First, we will create the vocabulary as shown below. Here, we are only adding those words in the vocabulary which are having term frequency >= 5.
num_train = 12000
UNK_symbol = "<UNK>"
vocab = set([UNK_symbol])
# create brown corpus again with all words
# no preprocessing, only lowercase
brown_corpus_train = []
for idx,paragraph in enumerate(brown.paras()):
if idx == num_train:
break
words = []
for sentence in paragraph:
for word in sentence:
words.append(word.lower())
brown_corpus_train.append(words)
# create term frequency of the words
words_term_frequency_train = {}
for doc in brown_corpus_train:
for word in doc:
# this will calculate term frequency
# since we are taking all words now
words_term_frequency_train[word] = words_term_frequency_train.get(word,0) + 1
# create vocabulary
for doc in brown_corpus_train:
for word in doc:
if words_term_frequency_train.get(word,0) >= 5:
vocab.add(word)
print(len(vocab))
## 12681
Now, we will create training and development set as per the trigram example shown above. Here, we are replacing words with their corresponding index in the constructed vocabulary so that they can be feed easily into the neural network.
import numpy as np
# create required lists
x_train = []
y_train = []
x_dev = []
y_dev = []
# create word to id mappings
word_to_id_mappings = {}
for idx,word in enumerate(vocab):
word_to_id_mappings[word] = idx
# function to get id for a given word
# return <UNK> id if not found
def get_id_of_word(word):
unknown_word_id = word_to_id_mappings['<UNK>']
return word_to_id_mappings.get(word,unknown_word_id)
# creating training and dev set
for idx,paragraph in enumerate(brown.paras()):
for sentence in paragraph:
for i,word in enumerate(sentence):
if i+2 >= len(sentence):
# sentence boundary reached
# ignoring sentence less than 3 words
break
# convert word to id
x_extract = [get_id_of_word(word.lower()),get_id_of_word(sentence[i+1].lower())]
y_extract = [get_id_of_word(sentence[i+2].lower())]
if idx < num_train:
x_train.append(x_extract)
y_train.append(y_extract)
else:
x_dev.append(x_extract)
y_dev.append(y_extract)
# making numpy arrays
x_train = np.array(x_train)
y_train = np.array(y_train)
x_dev = np.array(x_dev)
y_dev = np.array(y_dev)
print(x_train.shape)
print(y_train.shape)
print(x_dev.shape)
print(y_dev.shape)
## (872823, 2)
## (872823, 1)
## (174016, 2)
## (174016, 1)
So, we have finally constructed our training and development set. Now, let’s try to build and train our pytorch NPLM.
Bengio’s NPLM Architecture
Bengio’s N-gram language model architecture can be shown using below image.
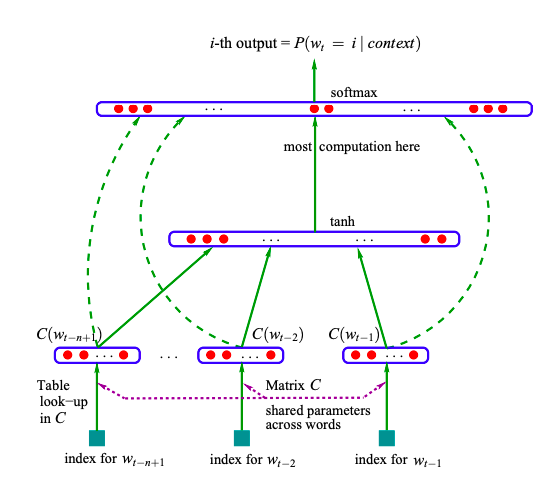
We can adapt this architecture for trigram by taking only 2 input words and predicting next word. This can be mathematically written as:
$x’ = e(x_1) \oplus e(x_2)$
$h = \tanh(W_1 x’ + b)$
$y = $ softmax$(W_2 h)$
where $\oplus$ is the concatenation operation, $x_1$ and $x_2$ are the input words, $e$ is an embedding function, and $y$ is the target word.
Now, if we take neural network with 100 hidden states and 200 size vectors for each word with 12681 vocabulary size, then above equation can be explained using their shapes as shown below.
embedding matrix = (12681 x 200)
e(x_1) = (1 x 200)
e(x_2) = (1 x 200)
x' = (1 x 200) concat (1 x 200) = (1 x 400)
W_1 = (100 x 400)
b = (1 x 100)
h = tanh(W_1 x' + b) = (1 x 100)
W_2 = (12681 x 100)
y = softmax(W_2 h) = (1 x 12681)
Here, matrix multiplication with right order can be achieved with pytorch. This calculation is just to show the different shapes of matrix and parameters. Hence, we are finally getting probability distribution of all the words in the vocabulary($y = 1 \times 12681$). We can take the word with maximum probability as our next predicted word.
This trigram model can be implemented in pytorch as shown below.
# load libraries
import torch
import multiprocessing
from torch import nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import DataLoader
import time
# Trigram Neural Network Model
class TrigramNNmodel(nn.Module):
def __init__(self, vocab_size, embedding_dim, context_size, h):
super(TrigramNNmodel, self).__init__()
self.context_size = context_size
self.embedding_dim = embedding_dim
self.embeddings = nn.Embedding(vocab_size, embedding_dim)
self.linear1 = nn.Linear(context_size * embedding_dim, h)
self.linear2 = nn.Linear(h, vocab_size, bias = False)
def forward(self, inputs):
# compute x': concatenation of x1 and x2 embeddings
embeds = self.embeddings(inputs).view((-1,self.context_size * self.embedding_dim))
# compute h: tanh(W_1.x' + b)
out = torch.tanh(self.linear1(embeds))
# compute W_2.h
out = self.linear2(out)
# compute y: log_softmax(W_2.h)
log_probs = F.log_softmax(out, dim=1)
# return log probabilities
# BATCH_SIZE x len(vocab)
return log_probs
Training and Saving Pytorch Model with GPU acceleration
First, we need to create dataloader for our training and development data. We will be using 100 hidden units with 200 word vectors size. We are also using 256 as the batch size for our dataloader.
# create parameters
gpu = 0
# word vectors size
EMBEDDING_DIM = 200
CONTEXT_SIZE = 2
BATCH_SIZE = 256
# hidden units
H = 100
torch.manual_seed(13013)
# check if gpu is available
device = 'cuda' if torch.cuda.is_available() else 'cpu'
available_workers = multiprocessing.cpu_count()
print("--- Creating training and dev dataloaders with {} batch size ---".format(BATCH_SIZE))
train_set = np.concatenate((x_train, y_train), axis=1)
dev_set = np.concatenate((x_dev, y_dev), axis=1)
train_loader = DataLoader(train_set, batch_size = BATCH_SIZE, num_workers = available_workers)
dev_loader = DataLoader(dev_set, batch_size = BATCH_SIZE, num_workers = available_workers)
We are also going to use some helper functions for testing accuracy on development data using below code.
# helper function to get accuracy from log probabilities
def get_accuracy_from_log_probs(log_probs, labels):
probs = torch.exp(log_probs)
predicted_label = torch.argmax(probs, dim=1)
acc = (predicted_label == labels).float().mean()
return acc
# helper function to evaluate model on dev data
def evaluate(model, criterion, dataloader, gpu):
model.eval()
mean_acc, mean_loss = 0, 0
count = 0
with torch.no_grad():
dev_st = time.time()
for it, data_tensor in enumerate(dataloader):
context_tensor = data_tensor[:,0:2]
target_tensor = data_tensor[:,2]
context_tensor, target_tensor = context_tensor.cuda(gpu), target_tensor.cuda(gpu)
log_probs = model(context_tensor)
mean_loss += criterion(log_probs, target_tensor).item()
mean_acc += get_accuracy_from_log_probs(log_probs, target_tensor)
count += 1
if it % 500 == 0:
print("Dev Iteration {} complete. Mean Loss: {}; Mean Acc:{}; Time taken (s): {}".format(it, mean_loss / count, mean_acc / count, (time.time()-dev_st)))
dev_st = time.time()
return mean_acc / count, mean_loss / count
Finally, we will create our model object, load it into gpu, set optimizer and starting training our model. We will be performing 5 epochs and save model only if it is giving good performance on the development set.
# Using negative log-likelihood loss
loss_function = nn.NLLLoss()
# create model
model = TrigramNNmodel(len(vocab), EMBEDDING_DIM, CONTEXT_SIZE, H)
# load it to gpu
model.cuda(gpu)
# using ADAM optimizer
optimizer = optim.Adam(model.parameters(), lr = 2e-3)
# ------------------------- TRAIN & SAVE MODEL ------------------------
best_acc = 0
best_model_path = None
for epoch in range(5):
st = time.time()
print("\n--- Training model Epoch: {} ---".format(epoch+1))
for it, data_tensor in enumerate(train_loader):
context_tensor = data_tensor[:,0:2]
target_tensor = data_tensor[:,2]
context_tensor, target_tensor = context_tensor.cuda(gpu), target_tensor.cuda(gpu)
# zero out the gradients from the old instance
model.zero_grad()
# get log probabilities over next words
log_probs = model(context_tensor)
# calculate current accuracy
acc = get_accuracy_from_log_probs(log_probs, target_tensor)
# compute loss function
loss = loss_function(log_probs, target_tensor)
# backward pass and update gradient
loss.backward()
optimizer.step()
if it % 500 == 0:
print("Training Iteration {} of epoch {} complete. Loss: {}; Acc:{}; Time taken (s): {}".format(it, epoch, loss.item(), acc, (time.time()-st)))
st = time.time()
print("\n--- Evaluating model on dev data ---")
dev_acc, dev_loss = evaluate(model, loss_function, dev_loader, gpu)
print("Epoch {} complete! Development Accuracy: {}; Development Loss: {}".format(epoch, dev_acc, dev_loss))
if dev_acc > best_acc:
print("Best development accuracy improved from {} to {}, saving model...".format(best_acc, dev_acc))
best_acc = dev_acc
# set best model path
best_model_path = 'best_model_{}.dat'.format(epoch)
# saving best model
torch.save(model.state_dict(), best_model_path)
--- Training model Epoch: 1 ---
Training Iteration 0 of epoch 0 complete. Loss: 9.481761932373047; Acc:0.0; Time taken (s): 0.3180065155029297
Training Iteration 500 of epoch 0 complete. Loss: 6.210723876953125; Acc:0.16796875; Time taken (s): 3.1815690994262695
Training Iteration 1000 of epoch 0 complete. Loss: 6.109804153442383; Acc:0.1328125; Time taken (s): 3.090549945831299
Training Iteration 1500 of epoch 0 complete. Loss: 6.035182952880859; Acc:0.15234375; Time taken (s): 3.0735549926757812
Training Iteration 2000 of epoch 0 complete. Loss: 5.9255547523498535; Acc:0.1171875; Time taken (s): 3.092804431915283
Training Iteration 2500 of epoch 0 complete. Loss: 6.280575275421143; Acc:0.1171875; Time taken (s): 3.092245101928711
Training Iteration 3000 of epoch 0 complete. Loss: 5.736732482910156; Acc:0.17578125; Time taken (s): 3.1062614917755127
--- Evaluating model on dev data ---
Dev Iteration 0 complete. Mean Loss: 5.041547775268555; Mean Acc:0.19921875; Time taken (s): 0.05501890182495117
Dev Iteration 500 complete. Mean Loss: 5.1310055936406; Mean Acc:0.1674853414297104; Time taken (s): 1.411548137664795
Epoch 0 complete! Development Accuracy: 0.16640816628932953; Development Loss: 5.144124689522911
Best development accuracy improved from 0 to 0.16640816628932953, saving model...
--- Training model Epoch: 2 ---
Training Iteration 0 of epoch 1 complete. Loss: 6.3111653327941895; Acc:0.13671875; Time taken (s): 0.058876991271972656
Training Iteration 500 of epoch 1 complete. Loss: 5.596146106719971; Acc:0.18359375; Time taken (s): 3.1026506423950195
Training Iteration 1000 of epoch 1 complete. Loss: 5.557393550872803; Acc:0.1875; Time taken (s): 3.0898776054382324
Training Iteration 1500 of epoch 1 complete. Loss: 5.647038459777832; Acc:0.171875; Time taken (s): 3.0894532203674316
Training Iteration 2000 of epoch 1 complete. Loss: 5.496565341949463; Acc:0.16015625; Time taken (s): 3.0931906700134277
Training Iteration 2500 of epoch 1 complete. Loss: 5.6066179275512695; Acc:0.15625; Time taken (s): 3.103193759918213
Training Iteration 3000 of epoch 1 complete. Loss: 5.268069267272949; Acc:0.2109375; Time taken (s): 3.096323013305664
--- Evaluating model on dev data ---
Dev Iteration 0 complete. Mean Loss: 5.003405570983887; Mean Acc:0.203125; Time taken (s): 0.0589292049407959
Dev Iteration 500 complete. Mean Loss: 5.109068775367356; Mean Acc:0.1724831610918045; Time taken (s): 1.4370334148406982
Epoch 1 complete! Development Accuracy: 0.17167776823043823; Development Loss: 5.120270270459792
Best development accuracy improved from 0.16640816628932953 to 0.17167776823043823, saving model...
--- Training model Epoch: 3 ---
Training Iteration 0 of epoch 2 complete. Loss: 5.93459415435791; Acc:0.1484375; Time taken (s): 0.060472726821899414
Training Iteration 500 of epoch 2 complete. Loss: 5.258722305297852; Acc:0.19140625; Time taken (s): 3.111907720565796
Training Iteration 1000 of epoch 2 complete. Loss: 5.276760101318359; Acc:0.22265625; Time taken (s): 3.1085517406463623
Training Iteration 1500 of epoch 2 complete. Loss: 5.393718242645264; Acc:0.1953125; Time taken (s): 3.0886611938476562
Training Iteration 2000 of epoch 2 complete. Loss: 5.29367208480835; Acc:0.16015625; Time taken (s): 3.1124625205993652
Training Iteration 2500 of epoch 2 complete. Loss: 5.236300945281982; Acc:0.19921875; Time taken (s): 3.0885303020477295
Training Iteration 3000 of epoch 2 complete. Loss: 5.008234977722168; Acc:0.2265625; Time taken (s): 3.0943117141723633
--- Evaluating model on dev data ---
Dev Iteration 0 complete. Mean Loss: 4.990195274353027; Mean Acc:0.203125; Time taken (s): 0.06059598922729492
Dev Iteration 500 complete. Mean Loss: 5.144070710012775; Mean Acc:0.17375405132770538; Time taken (s): 1.4334712028503418
Epoch 2 complete! Development Accuracy: 0.1728515625; Development Loss: 5.15414260485593
Best development accuracy improved from 0.17167776823043823 to 0.1728515625, saving model...
--- Training model Epoch: 4 ---
Training Iteration 0 of epoch 3 complete. Loss: 5.6557111740112305; Acc:0.16015625; Time taken (s): 0.06224703788757324
Training Iteration 500 of epoch 3 complete. Loss: 5.0387187004089355; Acc:0.19140625; Time taken (s): 3.106245756149292
Training Iteration 1000 of epoch 3 complete. Loss: 5.0854668617248535; Acc:0.20703125; Time taken (s): 3.1040847301483154
Training Iteration 1500 of epoch 3 complete. Loss: 5.223520755767822; Acc:0.19921875; Time taken (s): 3.105881690979004
Training Iteration 2000 of epoch 3 complete. Loss: 5.128862380981445; Acc:0.171875; Time taken (s): 3.087648630142212
Training Iteration 2500 of epoch 3 complete. Loss: 4.9816694259643555; Acc:0.203125; Time taken (s): 3.0943872928619385
Training Iteration 3000 of epoch 3 complete. Loss: 4.8544793128967285; Acc:0.234375; Time taken (s): 3.09727144241333
--- Evaluating model on dev data ---
Dev Iteration 0 complete. Mean Loss: 5.02003812789917; Mean Acc:0.203125; Time taken (s): 0.05782127380371094
Dev Iteration 500 complete. Mean Loss: 5.194172542252226; Mean Acc:0.17249874770641327; Time taken (s): 1.398315668106079
Epoch 3 complete! Development Accuracy: 0.17180033028125763; Development Loss: 5.203256042564616
--- Training model Epoch: 5 ---
Training Iteration 0 of epoch 4 complete. Loss: 5.449733734130859; Acc:0.17578125; Time taken (s): 0.05681610107421875
Training Iteration 500 of epoch 4 complete. Loss: 4.869087219238281; Acc:0.21484375; Time taken (s): 3.10964298248291
Training Iteration 1000 of epoch 4 complete. Loss: 4.914466857910156; Acc:0.22265625; Time taken (s): 3.102259397506714
Training Iteration 1500 of epoch 4 complete. Loss: 5.077721118927002; Acc:0.2109375; Time taken (s): 3.138408899307251
Training Iteration 2000 of epoch 4 complete. Loss: 4.9818243980407715; Acc:0.171875; Time taken (s): 3.1185004711151123
Training Iteration 2500 of epoch 4 complete. Loss: 4.776507377624512; Acc:0.2109375; Time taken (s): 3.125202178955078
Training Iteration 3000 of epoch 4 complete. Loss: 4.682910919189453; Acc:0.24609375; Time taken (s): 3.105964422225952
--- Evaluating model on dev data ---
Dev Iteration 0 complete. Mean Loss: 5.069443702697754; Mean Acc:0.20703125; Time taken (s): 0.059821128845214844
Dev Iteration 500 complete. Mean Loss: 5.247745371150399; Mean Acc:0.1709003895521164; Time taken (s): 1.4250988960266113
Epoch 4 complete! Development Accuracy: 0.17023782432079315; Development Loss: 5.255638471771689
Computing word similarities using saved model
Now, we can get the similarity index of some word pairs using cosine similarity and our saved model.
# ---------------------- Loading Best Model -------------------
best_model = TrigramNNmodel(len(vocab), EMBEDDING_DIM, CONTEXT_SIZE, H)
best_model.load_state_dict(torch.load(best_model_path))
best_model.cuda(gpu)
cos = nn.CosineSimilarity(dim=0)
lm_similarities = {}
# word pairs to calculate similarity
words = {('computer','keyboard'),('cat','dog'),('dog','car'),('keyboard','cat')}
# ----------- Calculate LM similarities using cosine similarity ----------
for word_pairs in words:
w1 = word_pairs[0]
w2 = word_pairs[1]
words_tensor = torch.LongTensor([get_id_of_word(w1),get_id_of_word(w2)])
words_tensor = words_tensor.cuda(gpu)
# get word embeddings from the best model
words_embeds = best_model.embeddings(words_tensor)
# calculate cosine similarity between word vectors
sim = cos(words_embeds[0],words_embeds[1])
lm_similarities[word_pairs] = sim.item()
print(lm_similarities)
{('keyboard', 'cat'): 0.00597948729991913,
('computer', 'keyboard'): 0.1643026947975159,
('cat', 'dog'): 0.18583052739501,
('dog', 'car'): 0.007236453145742416}
The above output clearly suggests that (keyboard,computer) and (dog,cat) are more similar from the prespective of context or the chance of co-occurrence as compared to (keyboard,cat) and (dog,car). This simple experiment can give more profound results if we are training our model for longer time.
The key takeaway from this post is the neat implementation support of pytorch for creating and training language models with the ease of GPU acceleration.
Complete colab notebook can be found here: https://colab.research.google.com/drive/1VNetYDvOZmUd2954tyViFfNEwoDQAbPW?usp=sharing



Leave a comment